4 What's going on
4.2 Index
It is not practical for the search engine to go looking at every page on the Web whenever it receives a search request. Instead, the search engine consults a vast index to the Web. This index is prepared in advance and is stored as a database to make retrieval as efficient as possible. The index of a search site is just like the index of a book – it contains a list of words, each with a reference to the page on which that word was found. The reference to the original page is, of course, a URL, so the search engine can provide you with a link to the page in the list of results.
An index of the Web is of course much larger than the index of any book. No search engine can claim to have indexed all the Web; it is too large and too rapidly changing for that to be possible. Even so, as mentioned above, Google currently claims to index some four billion web pages. And, what's more, the index is a full-text index: it notes the occurrence of each and every word on the page. (Actually, it ignores the commonest words such as ‘a’, ‘the’, ‘un’, and ‘le).
So how does that index get built? There are three routes by which web pages get into the index.
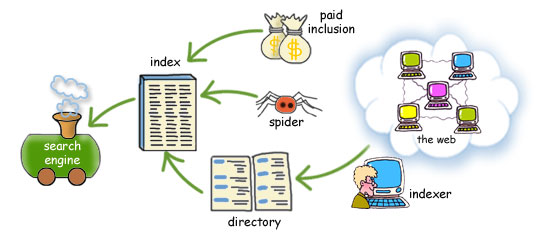
4.2.1 Paid inclusion
Companies and organisations can pay to have their web pages included. Results from paid inclusion are usually picked out in the list of hits, for example by being labelled as a ‘sponsored link’. Paid inclusion provides income for the search site. Arguably, sponsored links can be valuable to the searcher; no company is going to waste money on directing you to a page that isn't of use to you.
4.2.2 Classified directory
Some pages are added because a researcher has chosen them. The researcher reads the page, categorises it, writes a short description, and adds it to a classified directory. The best known example of this approach is Yahoo!, which employs people to scour the Web for useful sites and add them to the Yahoo! directory. Google relies on the Open Directory, a project that allows volunteers to contribute useful sites in the same way. One advantage of this approach is that it benefits from human judgement on the quality of the page. Another advantage is that using a limited set of categories and keywords reduces problems arising from the use of synonyms such as ‘Internet’ and ‘Net’. But the cost and sheer impossibility with keeping up with the growth of the Web mean that a directory can never be exhaustive or complete.
4.2.3 Spider
By far the largest number of pages are added to the index automatically by a software spider (also called a ‘crawler’, ‘robot’ or ‘bot’) which crawls over the Web. The spider downloads a page, indexes every word that appears on it, and then follows each link that it finds on the page, repeating the process for the new page. The benefit of the spidering approach is coverage: spiders can cover far more sites and pages than human readers ever could, and they can revisit rapidly changing sites such as news sites frequently. A disadvantage is the lack of human judgement on the quality of the page.
Spiders find new web pages because they follow links from existing websites. But it may take time for a spider to find a new site, so search sites usually provide a facility for anyone to submit their website for spidering.